I’ve been enjoying using Go’s database/sql package for working with
databases. Recently, some mentions of gorm piqued my
curiosity about using ORMs in Go vs. using database/sql directly. Having had
some mixed experiences with ORMs in the past, I decided to start with a
practical experiment by writing the same simple application with and without
gorm, and comparing the results in terms of effort spent.
This led me to write down some general thoughts on the benefits and drawbacks
of ORMs. If that kind of thing interests you, read on!
My no-ORM vs. ORM experiment
My experiment involves defining a simple database that could be a subset of
a blogging engine, as well as write some Go code that populates and queries this
database and compare how it looks using plain SQL vs. using an ORM.
This is the database schema:
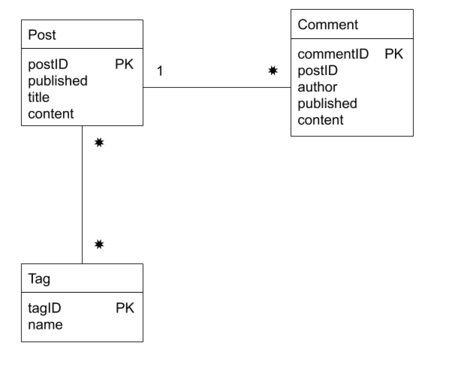
While simple, this schema demonstrates an idiomatic normalized database that
most likely contains all the elements one needs to build simple wiki or blog
apps – it has both one-to-many relationships (between posts and comments) and
many-to-many relationships (between posts and tags). If you prefer to read DB
schemas as SQL, here’s the definition taken from the code sample:
create table Post (
postID integer primary key,
published date,
title text,
content text
);
create table Comment (
commentID integer primary key,
postID integer,
author text,
published date,
content text,
-- One-to-many relationship between Post and Comment; each Comment
-- references a Post it's logically attached to.
foreign key(postID) references Post(postID)
);
create table Tag (
tagID integer primary key,
name text unique
);
-- Linking table for the many-to-many relationship between Tag and Post
create table PostTag (
postID integer,
tagID integer,
foreign key(postID) references Post(postID),
foreign key(tagID) references Tag(tagID)
);
This SQL was tested with SQLIte; other RDBMSs may need minor adjustments. When
using gorm, there is no need to write this SQL. Instead, we define “objects”
(really structs) with some magic field tags for gorm:
type Post struct {
gorm.Model
Published time.Time
Title string
Content string
Comments []Comment `gorm:"foreignkey:PostID"`
Tags []*Tag `gorm:"many2many:post_tags;"`
}
type Tag struct {
gorm.Model
Name string
Posts []*Post `gorm:"many2many:post_tags;"`
}
type Comment struct {
gorm.Model
Author string
Published time.Time
Content string
PostID int64
}
The code
working with this database comes in two variants:
- No-ORM; using plain SQL queries through the database/sql package.
- ORM; using the gorm library for database access.
The sample is doing several things:
- Add some data (posts, comments, tags) to the DB.
- Query all posts in a given tag.
- Query all post details (all comments attached to it, all tags it’s marked
with).
Just as an example, here are the two variants for task (2) – finding all posts
in a given tag (this could be to populate some sort of archives listing page
on the blog). First, no-ORM:
func dbAllPostsInTag(db *sql.DB, tagID int64) ([]post, error) {
rows, err := db.Query(`
select Post.postID, Post.published, Post.title, Post.content
from Post
inner join PostTag on Post.postID = PostTag.postID
where PostTag.tagID = ?`, tagID)
if err != nil {
return nil, err
}
var posts []post
for rows.Next() {
var p post
err = rows.Scan(&p.Id, &p.Published, &p.Title, &p.Content)
if err != nil {
return nil, err
}
posts = append(posts, p)
}
return posts, nil
}
This is fairly straightforward if you know SQL. We have to perform an
inner join between Post and PostTag and filter it by the tag ID. The
rest of the code is just iterating over the results.
Next, the ORM:
func allPostsInTag(db *gorm.DB, t *Tag) ([]Post, error) {
var posts []Post
r := db.Model(t).Related(&posts, "Posts")
if r.Error != nil {
return nil, r.Error
}
return posts, nil
}
In the ORM code, we tend to use objects directly (Tag here) rather than
their IDs, for the same effect. The SQL query generated by gorm here will be
pretty much the same as the one I wrote manually in the no-ORM variant.
Apart from generating the SQL for us, gorm also provides an easier way to
populate a slice of results. In the code using database/sql we explicitly
loop over the results, scanning each row separately into individual struct
fields. gorm’s Related method (and other similar querying methods) will
populate structs automatically and will also scan the whole result set in one
go.
Feel free to play with the code! I
was pleasantly surprised at the amount of code gorm saves here (about 50%
savings for the DB-intensive part of the code), and for these simple queries
using gorm wasn’t hard – the invocations are taken from API docs in a
straightforward manner. The only complaint I have about my specific example is
that setting up the many-to-many relationship between Post and Tag was a
bit finicky, and the gorm struct field tags look ugly and magical.
Layered complexity rears its ugly head
The problem with simple experiments like that above is that it’s often difficult
to tickle the system’s boundaries. It obviously works well for simple cases, but
I was interested to find out what happens when it’s pushed to the limit – how
does it handle complicated queries and DB schemas? So I turned to browsing
Stack Overflow. There are many gorm-related questions, and sure enough, the
usual layered complexity problem is immediately apparent (example 1,
example 2).
Let me explain what I mean by that.
Any situation where complex functionality is wrapped in another layer runs the
risk of increasing the overall complexity when the wrapping layer is itself
complicated. This often comes along with leaky abstractions – wherin the
wrapping layer can’t do a perfect job wrapping the underlying functionality, and
forces programmers to fight with both layers simultaneously.
Unfortunately, gorm is very susceptible to this problem. Stack Overflow has
an endless supply of problems where users end up fighting complexities imposed
by gorm itself, working around its limitations, and so on. Few things are
as aggravating as knowing exactly what you want (i.e. which SQL query you want
it to issue) but not being able to concoct the right sequence of gorm calls
to end up with that query.
Pros and Cons of using an ORM
One key advantage of using an ORM is apparent from my experiment: it saves quite
a bit of tedious coding. About 50% savings in DB-centered code is nontrivial
and can make a real difference for some applications.
Another advantage that wasn’t obvious here is abstraction from different
database backends. This may be less of an issue in Go, however, since
database/sql already provides a great portable layer. In languages that
lack a standardized SQL access layer, this advantage is much stronger.
As for the disadvantages:
- Another layer to learn, with all the idiosyncracies, special syntax, magical
tags, and so on. This is mainly a disadvantage if you’re already experienced
with SQL itself. - Even if you’re not experienced with SQL, there is a vast bank of knowledge
out there and many folks who can help with answers. Any single ORM is much
more obscure knowledge not shared by many, and you will spend considerable
amounts of time figuring out how to force-feed it things. - Debugging query performance is challenging, because we’re abstracted
one level further from “the metal”. Sometimes quite a bit of tweaking is
required to get the ORM to generate the right queries for you, and this is
frustrating when you already know which queries you need.
Finally, a disadvantage that only becomes apparent in the long term: while SQL
stays pretty much constant over the years, ORMs are language-specific and also
tend to appear and disappear all the time. Every popular language has a large
variety of ORMs to choose from; as you move from one team/company/project to
another, you may be expected to switch, and that’s additional mental burden. Or
you may switch languages altogether. SQL is a much more stable layer that stays
with you across teams/languages/projects.
Conclusion
Having implemented a simple application skeleton using raw SQL and compared it
to an implementation using gorm, I can see the appeal of ORMs in reducing
boilerplate. I can also remember myself from many years ago being a DB newbie
and using Django with its ORM to implement an application – it was nice! I
didn’t have to think about SQL or the underlying DB much, it just worked. But
that use case was really simple.
With my “experienced and salty” hat on, I can also see many disadvantages in
using an ORM. Specifically, I don’t think an ORM is
useful for me in a language like Go which already has a good SQL interface
that’s mostly portable across DB backends. I’d much rather spend an extra bit
of time typing, but this will save me time reading ORM’s documentation,
optimizing my queries, and most importantly debugging.
I could see an ORM still being useful in Go if your job is to write large
numbers of simple CRUD-like applications, where the savings in typing overcome
the disadvantages. In the end, it all boils
down to the central thesis of the benefits of extra dependencies as a function
of effort:
where there is significant effort to spend on a project outside the
DB-interfacing code – which should be the case for programs that aren’t simple
CRUDs – the ORM dependency is not worth it, in my opinion.
