Story of a Service
Suppose you’re writing a simple service: it handles inbound requests from your users, but doesn’t hold any data itself. This means that in order to handle any inbound requests it needs to refer to a backend to actually fetch whatever is required. This is a great feature as it means your service is stateless — it’s easier to test, simpler to scale, and typically easier to understand. In our story, you’re also lucky as you only handle a single request at a time with a single worker doing the work.
Your service diagram might look like this:
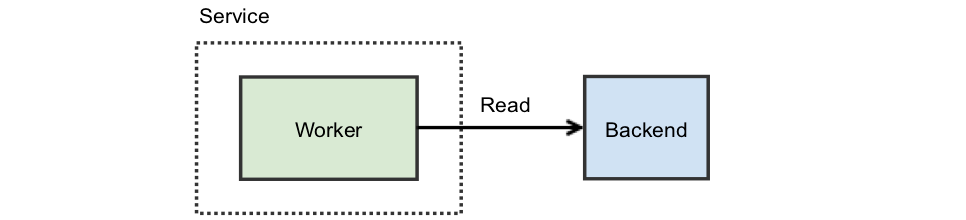
All is well but latency is an issue. The backend you use is slow. To address this, you notice that the vast majority — perhaps 90% — of the requests are the same. One common solution is to introduce a cache: before hitting the backend, you check your cache and use that value if present.
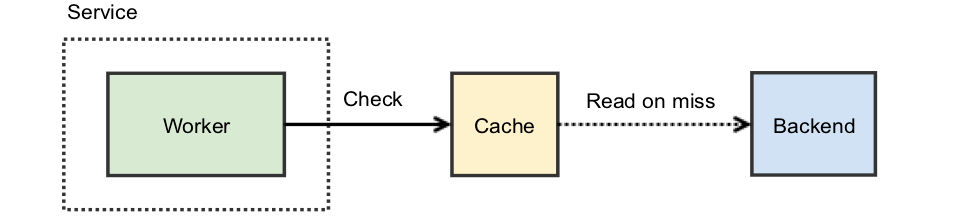
With the above design, 90% of incoming requests do not hit the backend. You’ve just reduced your resource requirements by 10x!
Of course, there are some additional details you now need to consider. Namely, what happens if the cache is erased, or if a brand new request appears? In either scenario, your assumption of 90% similarity is broken. There are many ways you may choose to work around this, for example:
- If the cache is erased because you’ve had to restart the service, you could consider making the cache external:
a) Leveraging memcache, or some other external caching service.
b) Using local disk as something “external” to your service you can load on startup.
c) Using something clever with shared memory segments to restart without discarding the in-memory state. - If the request is a brand new feature, you could handle it incrementally:
a) Deploy the new client that makes the request slowly, or adjust your distribution plans so it’s not all at once.
b) Have your service perform some sort of warmup, perhaps with fake requests emulating what you expect.
Furthermore, your service might not actually live alone. You might have lots of other instances of it, and an existing instance could be communicated with to accelerate your cache warmup routine.
All of these add complexity, some of them add intricate failure modes or make your service just more troublesome to deal with (what do you mean I can’t dial everything to 100% immediately?). Chances are your cache warms pretty quickly, and the less boxes on your service diagram the less things go wrong. Ultimately, you’re happy with doing nothing.
The Reality
The above diagram isn’t really what your service looks like. It’s a runaway success and each service is doing quite a lot of work. Your service actually looks like this:
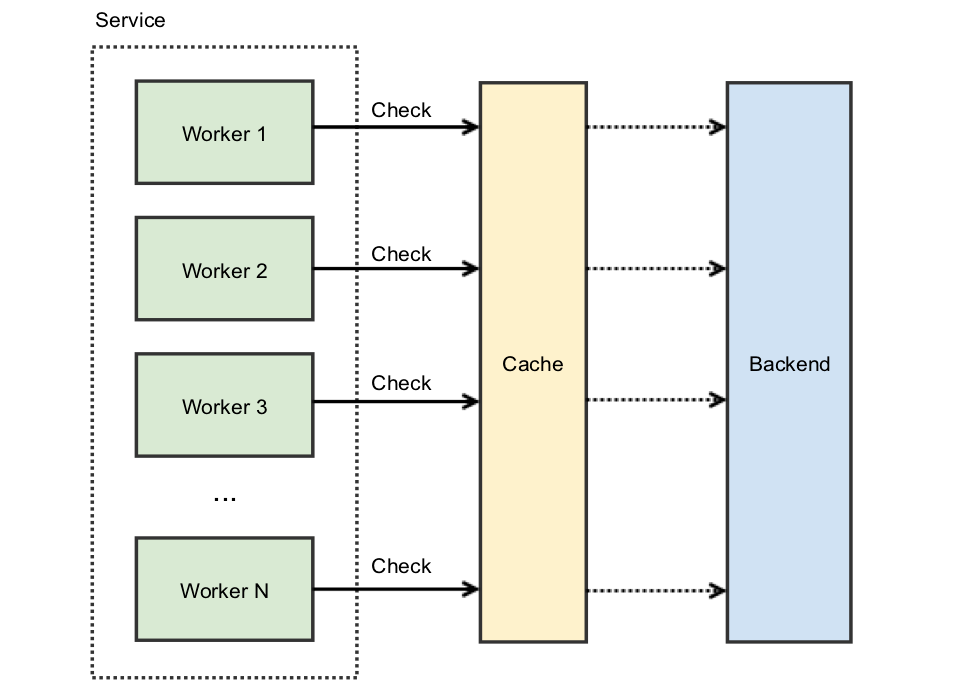
However, the cache-empty case is now much more problematic. To illustrate: if your cache is hit with 100 concurrent requests, then, since the cache is empty, all of them will get a cache-miss at the one moment, resulting in 100 individual requests to the backend. If the backend is unable to handle this surge of concurrent requests (ex: capacity constraints), additional problems arise. This is what’s sometimes called a thundering herd.
What to do?
The aforementioned alleviation scenarios may help improve the resilience of the cache — if you have a service-start resilient cache you can be safe to continually push things without worrying that this would cause awfulness. But this still doesn’t help you for the genuinely new request.
When you see a new request, by definition it is not in the cache, and in addition it may not even be predictable! You have many clients, they don’t always tell you about this in advance. Your only option is to slow the release of new features in order to pre-warm the cache, and hope everyone does this… or is it?
Promises
A Promise is an object that represents a unit of work producing a result that will be fulfilled at some point in the future. You can “wait” on this promise to be complete, and when it is you can fetch the resulting value. In many languages there is also the idea of “chaining” future work once the promise is fulfilled.
At Instagram, when turning up a new cluster we would run into a thundering herd problem as the cluster’s cache was empty. We then used promises to help solve this: instead of caching the actual value, we cached a Promise that will eventually provide the value. When we use our cache atomically and get a miss, instead of going immediately to the backend we create a Promise and insert it into the cache. This new Promise then starts the work against the backend. The benefit this provides is other concurrent requests will not miss as they’ll find the existing Promise — and all these simultaneous workers will wait on the single backend request.
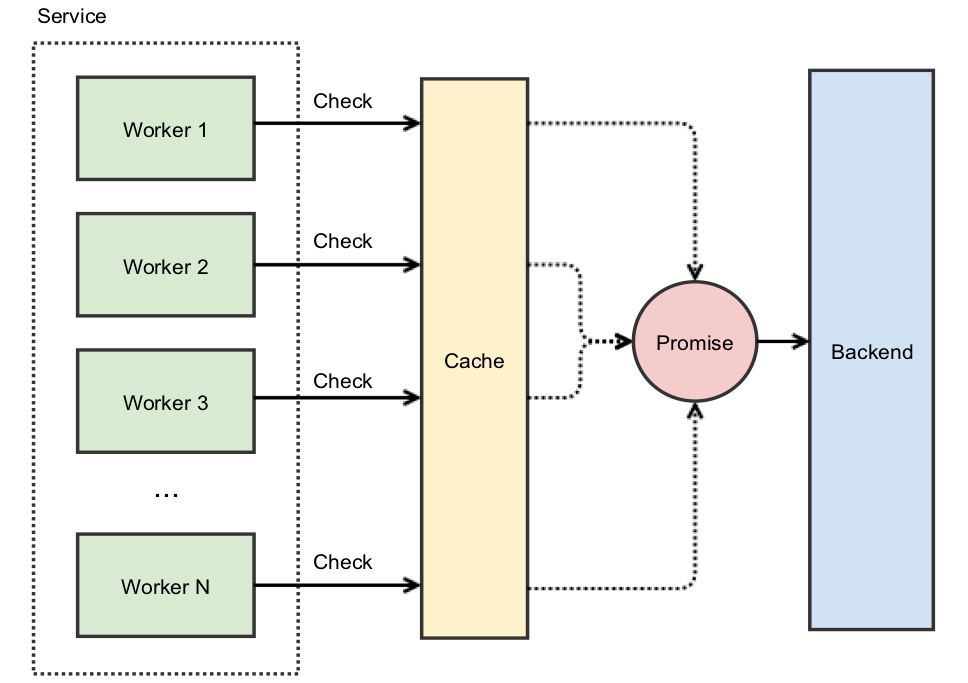
The net-effect is you’re able to maintain your assumptions around caching of requests. Assuming your request distribution has the property that 90% are cache-able; then you’d maintain that ratio to your backend even when something new happens or your service is restarted.
We manage so many different services at Instagram that reducing the amount of traffic to our servers via Promise-based caches has real stability benefits.
