Heroku has many public API endpoints. Each of these endpoints needs to be tested so that we know how they work, and documented so that our customers (and other API consumers) know how they work. Follow along, and we’ll learn how Heroku uses JSON Schema to test and document our Platform API – and how it helped us uncover an unexpected bug, rooted in the way the Oj gem parses Big Decimals.
JSON Schema files are like blueprints that define the structure and semantics of other JSON documents. When a JSON Schema file is applied to a JSON document, you can determine whether the document is valid (conforms to the schema) or is invalid (does not conform to the schema).
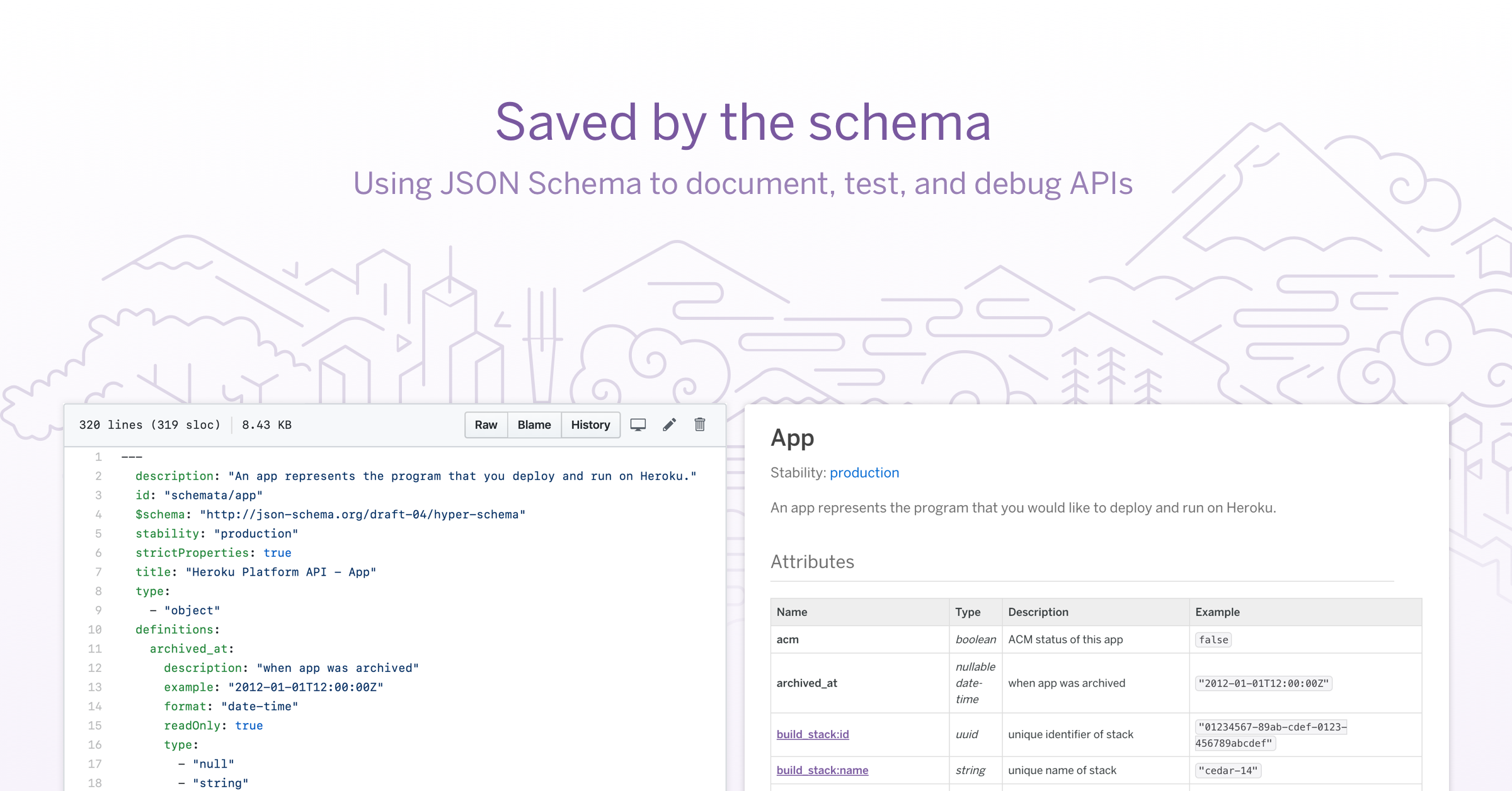
So how do we at Heroku use JSON Schema to document and test our public API?
One of the most important parts of maintaining a public API is making sure that the documentation is always up to date.
One way Heroku’s engineering team ensures that our public API docs are correct is a rake task invoked by our CI service. The rake task checks for any changes to JSON schema files in the current branch. If there are changes, it uses prmd to translate those updated JSON schema files into a markdown file. When the changes are deployed, that markdown file is published as our public Platform API Reference.
Documenting API endpoints via JSON Schema is better than updating docs in a manual, ad-hoc manner, but this process does not ensure that the docs are accurate. To verify the accuracy of the docs generated by JSON Schema files, API requests and responses must be validated against the JSON Schema files.
In the Platform API’s test suite, we use the committee gem to see that JSON responses from our API match the structure of the corresponding JSON Schema files. If the test for an endpoint passes the assert_schema_conform method provided by the committee gem, we know that our API requests and responses match the definitions in JSON Schema. If the test fails assert_schema_conform, we know that we either need to change our JSON Schema definitions or we need to update the API endpoint itself to match the corresponding JSON Schema file.
When we at Heroku started testing our API with committee it immediately uncovered some inconsistencies between the existing JSON Schema files and what various API endpoints actually returned – and it turns out to be a gift that keeps giving.
One challenge of writing tests, in general, is writing tests that sufficiently cover all real life edge cases. Writing tests that compare API responses and JSON Schema files are no exception.
Recently, I was working on a feature for our Heroku Enterprise users which allows them to retrieve monthly or daily usage data for their accounts or teams. We were doing some initial curl requests of the new endpoints when we noticed something strange: when the dyno usage value was a decimal number, it was a string. When the dyno usage value was an integer, it was a number.
In our API docs, I saw that the dynos value was defined as a number. Because our API docs are generated from JSON Schema, I knew the docs were probably reflecting our JSON Schema files.
I went back to our JSON Schema file for the endpoint, which included the following definition:
"dynos": {
"description": "dynos used",
"example": 1.548,
"readonly": true,
"type": [
"number"
]
}
So, according to the JSON Schema definition, we should have expected a number. To test what I was seeing in my curl requests, I wrote a new test for a team where the dyno usage was a number with many decimal places. When I ran the new test using the committee gem’s assert_schema_conform method, I got the following error:
Failure/Error: assert_schema_conform
Committee::InvalidResponse:
Invalid response.
#/0/dynos: failed schema #/definitions/team-usage/properties/dynos: For 'properties/dynos', "1967.4409999999837" is not a number.
Good news! I reproduced what I was seeing in production: sometimes, the dynos value came back as a string (number in quotes) rather than a number as we expected. Just to make sure, I ran the old test (for a team where the dyno usage was an integer), and the assert_schema_conform check passed. So in that case, the dynos value was a number like the schema expected. Good news again! I reproduced the case where the dynos value was a number. Now to figure out why….
Because both responses were passing through the same serializer, the only possible answer was that something was happening in the JSON parsing of these values. In our endpoints, we serialize responses and then call MultiJson.dump(object). MultiJson is just “a generic swappable back-end for JSON handling” so in order to debug further I needed to look at which parsing adapter we were using. In our case, it was Oj.
In an irb session, I ran the following:
require 'multi_json'
=> true
MultiJson.use :oj
=> MultiJson::Adapters::Oj
MultiJson.load('0').class
=> Integer
MultiJson.load('1967.44').class
=> Float
MultiJson.load('1967.4409999999837').class
=> BigDecimal
That all looks as expected. But when digging further, my issue became more obvious:
MultiJson.dump(MultiJson.load('0'))
=> "0"
irb(main):002:0> MultiJson.dump(MultiJson.load('1967.44'))
=> "1967.44"
MultiJson.dump(MultiJson.load('1967.4409999999837'))
=> ""1967.4409999999837""
Bingo! MultiJson is parsing numbers with many decimal places (a BigDecimal) differently from other numbers (note the extra set of quotes around the return value).
After looking through the Oj repo, I found the following comment from the maintainer:
the json gem and Rails use a string format for BigDecimal. Oj now does its best to mimic both so it now returns a string as well.
Although our API does not run on Rails, I was interested to know why Rails parses BigDecimals as strings. From the docs:
A BigDecimal would be naturally represented as a JSON number. Most libraries, however, parse non-integer JSON numbers directly as floats. Clients using those libraries would get in general a wrong number and no way to recover other than manually inspecting the string with the JSON code itself.
That’s why a JSON string is returned. The JSON literal is not numeric, but if the other end knows by contract that the data is supposed to be a BigDecimal, it still has the chance to post-process the string and get the real value.
In short, Oj parses BigDecimals as strings because Rails parses BigDecimals as strings. And Rails parses BigDecimals as strings to allow greater specificity.
If our API endpoint wanted to have the greatest level of specificity possible, it’s likely we would have kept this default behavior and perhaps cast all values of this field as strings. While it is possible to define a field in JSON Schema as being either a string or a number, doing so would not be desireable in terms of API design. This is because it is good API design to always return the same data type for a given value (i.e., the API consumer may not always know which number they will receive, but they know it will always be a number rather than a string, array, hash, etc.).
Floating point numbers in Ruby are limited to a precision of 15 decimal places and, for the dyno value in this API endpoint, 15 decimal places was plenty, so casting as a float was fine. To prevent Oj from casting BigDecimals as strings, we updated our app’s MultiJson config to:
MultiJson.use :oj
MultiJson.load_options = {
bigdecimal_load: :float,
}
And when I re-ran the assert_schema_conform test for a team with a BigDecimal dyno value, it passed, so I knew that our schema, and therefore our docs, were reflecting the real returned values from our API.
Heroku’s use of JSON Schema, prmd, and the committee gem made it easy to test, validate, and document that the API was now parsing BigDecimals as floats rather than strings.
