Shaping
When laying out text using a font file, the code points in the string are mapped one-to-one to glyphs inside the file. A glyph is a little picture inside the font file, and is identified by ID, which is a number from 0 – 65535. However, there’s a step after character mapping but before rasterization: shaping.
For example, one application of shaping is seen in Arabic text. In Arabic, each letter has four different forms, depending on which letters are next to it. For example, two letters in their isolated form look like ف and ي but as soon as you put them together, they form new shapes and look like في. This type of modification isn’t possible if characters are naively mapped to glyphs and then rasterized directly. Instead, there needs to be a step in the middle to modify the glyph forms so the correct thing is rasterized.
This “middle step” is called shaping, and is implemented by three tables inside the OpenType font file: GSUB, GPOS, and GDEF. Let’s consider GSUB alone.
GSUB
The GSUB table, or “glyph substitution” table, is designed to let font authors replace glyphs with other glyphs. It describes a transformation where the input is a sequence of glyphs and the output is a different sequence of glyphs. It is made up of a collection of constituent “lookup tables,” each of which has a “type.”
Type 1 (“single substitution”) provides a map from glyph to glyph. This is used for example, when someone enables the ‘swsh’ feature, the font can substitute out the ampersand with a fancy ampersand. In that situation, the map would contain a mapping from the regular ampersand to the fancy ampersand (possibly in addition to some more additional mappings, too).
Type 2 (“multiple substitution”) provides a map from glyph to sequence-of-glyphs. This is used, for example, if diacritic (accent) marks are represented as separate glyphs inside the font. The font can replace the “è” glyph with the “e” glyph followed by the ◌̀ glyph (and then the GPOS table later can position the two glyphs physically on top of each other).
Type 4 (“ligature substitution”) provides a map of sequence-of-glyphs to single glyph (the opposite of type 2). This is used for ligatures, so if you have a fancy “ffi” ligature, you can represent all three of those letters in the same fancy glyph.
Type 5 (“contextual substitution”) is special. It doesn’t do any replacements directly, but instead maps a sequence of glyphs to a list of other tables that should be applied at specific points in the glyph sequence. So it can say things like “in the glyph sequence ‘abcde’, apply table #7 at index 2, and then when you’re done with that, apply table #13 at index 4.” Tables #7 and #13 can be any of the types above, so you could use this table to say something like “swap out the ‘d’ for an ‘f’, but only if it appears in the sequence ‘abcde’.” This sort of thing is used to implement the “contextual alternates” feature.
There are also three other types, but they’re not particularly relevant, so I’m going to ignore them.
So, the inputs to the text system are a set of features and an input string of glyphs (The characters have already been mapped to glyphs via the “cmap” table). Features are mapped to a set of lookup tables, each of which is of a type listed above. Each of those lookup tables describes a map where the keys are sequences of glyphs, so the runtime iterates through the glyph sequence until it finds a sequence that’s an input to one of the tables. The runtime then performs that glyph replacement according to the rules of the tables, and continues iterating.
Turing Complete
So this is pretty cool, but it turns out that the contextual substitution lookup type is really powerful. This is because the table that it references can be itself, which means it can be recursive.
Let’s pretend we have a lookup table named 42 (presumably because it’s the 42nd lookup table inside the font), and it’s a contextual substitution lookup table. This table maps glyph sequences to tuples of (lookup table to recurse to, offset in glyph sequence to recurse). Let’s say we design it with these two mappings:
Table42 {
A A : (Table42, 1);
A B : (Table100, 1);
}
If the runtime is operating on a glyph sequence of “AAAAB”, the first two “AA”s will match the first rule, so then the system recurses and runs Table42 on the stream “AAAB”. Then these first two “AA”s will match, and so-on. This happens until you get to the end of the string, “AB” matches, and then Table100 is run on the string “B”.
This is “tail recursion,” and can be used to implement all different types of loops. Also, each mapping in the table acts as an “if” statement because it only executes if the pattern is matched.
You can use the glyph stream as memory by reading and writing to it; that is, after all, what the shaping algorithm is designed to do. You can delete a glyph by using Type 2 to map it to an empty sequence. You can insert a glyph by using Type 2 to map the preceding glyph to a sequence of [itself, the new glyph you want to insert]. And, once you’ve inserted a glyph, you can check for its presence by using the “if” statements described above.
So thats a pretty powerful virtual machine. I think the above is sufficient to prove Turing complete-ness.
Caveat
So it turns out the example (“
Table42”) above doesn’t actually work in DirectWrite. This is because, in DirectWrite, inner matches have to be entirely contained within outer matches. So when the outer call to
Table42 matched “
AA”, the inner call to
Table42 can only match within that specific “
AA”. This means it’s impossible to, for example, find the first even glyphID and move it to the beginning. So, DirectWrite’s implementation isn’t Turing complete. However, it does work in HarfBuzz and CoreText, so those implementations are Turing complete.
But even in HarfBuzz and CoreText, there are hard limits on the recursion depth. HarfBuzz sets its limit to 6. Therefore, the above example will only work on strings of length 7 or fewer. HarfBuzz is open source, though, so I simply used a custom build of HarfBuzz which bumps up this limit to 4 billion. This let me recurse to my heart’s content. A limit of 6 is probably a good thing; I don’t think users generally expect their text engines to be running arbitrary computation during layout. But I want to go beyond it.
DSL
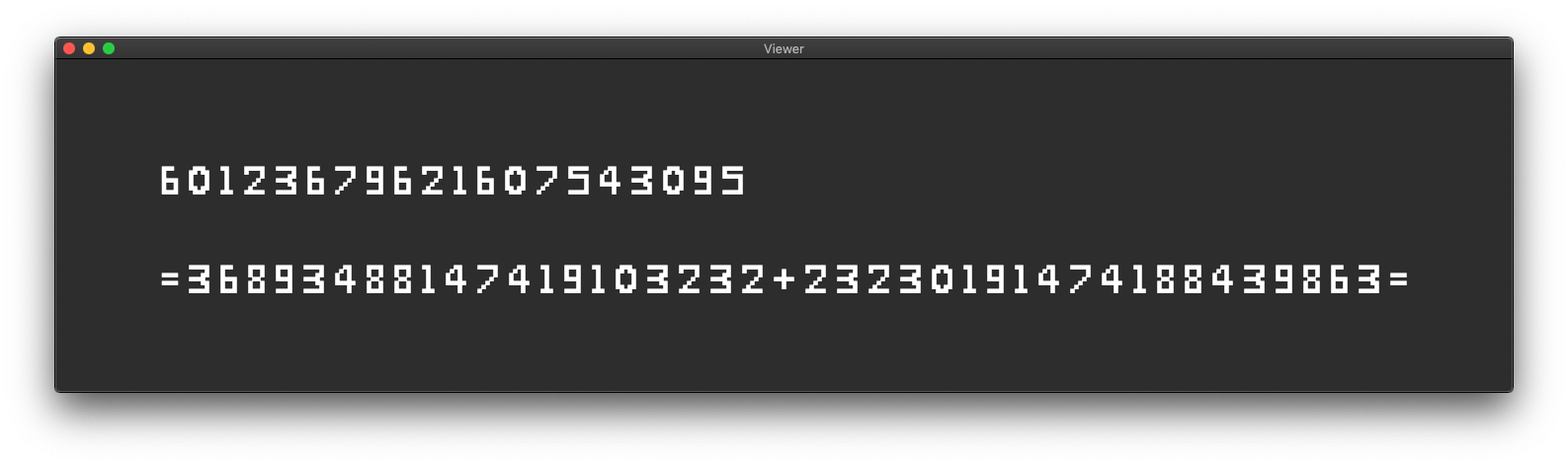
After making the above realizations, I decided to try to implement a nontrivial algorithm using only the GSUB table in a font. I wanted to try to implement addition. The input glyph stream would be of the form “
=1234+5678=” and the shaping process would turn that string into “
6912”.
When thinking about how to do this, I started jotting down some ideas on paper for what the lookup tables should be, and the things I were writing down were very similar to that “Table42” example above. However, writing down tables of types 1, 2, and 4 was quite cumbersome, because what I really wanted to describe were things like “move this glyph to the beginning of the sequence” rather than individual insertions or deletions.
I looked at the “fea” language, which is how these lookups are traditionally written by font designers. However, after reading the parser, it looks like it doesn’t support recursive or mutually-recursive lookups. So, I rolled my own.
So, I did what any good programmer does in this situation: I invented a new domain-specific language.
The DSL has two types of statements. The first is a way of giving a set of glyphs a name. I wanted to be able to address all of the digits without having to write out every individual digit. So, there’s a statement that looks like this:
digit: 1 2 3 4 5 6 7 8 9 10;
Note that those numbers are glyph IDs, not code points. In my specific font, the “0” character is mapped to glyph 1, “1” is mapped to glyph 2, etc.
Then, you can describe a lookup using the syntax above:
digitMove {
digit digit: (1, digitMove), (1, digitMove2);
digit plus: (1, digitMove2);
}
The lookup is named digitMove, and it has two rules inside it. The first rule matches any two digits next to each other, and if they match, it invokes the lookup named digitMove (which is the name of the current lookup, so this is recursive) at index 1, and then after that, invokes the lookup named digitMove2 at index 1.
Each of these stanzas gets translated fairly trivially to lookup with type 5.
These rules are recursive, as above, but they need a terminal form so that the recursion will eventually end. Those are described like this:
flagPayload {
digit digit plus digit: flag 3 1 2;
}
This rule is a terminal because there are no parentheses on the right side of the colon. The right side represents a glyph sequence to replace the match with. The values on the right side are either a literal glyph ID, a glyph set that contains exactly one glyph, or a backreference which starts with a backslash. “3” means “whatever glyph was third glyph in the matched sequence”. So the rule above would turn the glyph sequence “34+5” into the sequence “F534+”. (The flag glyph is read and removed in a later stage of processing).
Translating one of these rules to lookups is nontrivial. I tried a few things, but ended up with the following design:
For each output glyph, right to left:
- If it’s a backreference, duplicate the glyph it’s referencing, and perform a sequence of swaps to move the new glyph all the way to the right.
- If it’s a literal glyph, insert it at the beginning, and perform a sequence of swaps to move it all the way to the right.
This means we need to have a way to do the following operations:
- Duplicate. This is a type 4 lookup that maps every glyph to a sequence of two of that glyph.
- Swap. This has two pieces: a type 5 lookup that has a rule for every combination of two glyphs, and each rule maps each glyph to a lookup of type 1 which replaces it with the appropriate glyph. This means you need n of these inner (type 1) lookups, allowing you to map any glyph to any other glyph. However, the encoding format allows us to encode each of these inner lookups in constant space in the font, so these inner lookups don’t take that much space. Instead, the outer type 5 lookup takes n^2 space.
- Insert a literal. If you implemented this by simply making a type 2 that mapped every glyph to that same glyph + the literal, you would need n^2 space because there would be n of these tables. Instead, you can cut down the size by doing it in two phases: inserting a flag glyph (which is O(n) space using a lookup type 2) and mapping that glyph to any constant value (also O(n) space using a type 1).
Above, I’m worried about space constraints in the file because pointers in the file are (in general) 2 bytes, meaning the maximum size that anything can be is 2^16. If n^2 space is needed, that means n can only be 2^8 = 256, which isn’t that big. Most fonts have on the order of 256 glyphs. Therefore, we need to reduce the places where we require O(n^2) space as much as possible. LookupType 7 helps somewhat, because it allows you to use 32-bit pointers in on specific place, but it only helps that one place.
My font only has 14 glyphs in it, so i didn’t end up near any of these limits, but it’s still important to watch out for out-of-bounds problems.
So, given all that, we can make a parser which builds an AST for the language, and we can build an intermediate representation which represents the bytes in the file, and we can make a lowering phase which lowers the AST to the IR. Then we can serialize the IR and write out the data to the file.
Addition
So, once the language was up and running, I had to actually write a program that represented addition. It works in four phases.
First, define some glyphs:
digit: 1 2 3 4 5 6 7 8 9 10;
flag: 13;
plus: 11;
equals: 12;
digit0: 1;
Then, parse the string. If the string didn’t match the form “=digits+digits=” then I wanted nothing to happen. You can do this by recursing across the string, and if you find that it matches the pattern, insert a flag, and then when all the calls return, move the flag leftward.
parse {
equals digit: (1, parseLeft), (0, afterParse);
}
parseLeft {
digit digit: (1, parseLeft), (0, moveFlagAcrossDigit);
digit plus digit: (2, parseRight), (0, moveFlagAcrossPlus);
}
parseRight {
digit digit: (1, parseRight), (0, moveFlagAcrossDigit);
digit equals: flag 1;
}
moveFlagAcrossDigit {
digit flag digit: 1 2;
}
moveFlagAcrossPlus {
digit plus flag digit: 2 1 3;
}
afterParse {
equals flag: (0, removeFlag), (0, startDigitMove);
}
removeFlag {
equals flag: ;
}
The next step is to pair up the glyphs. For example, this would turn “1234+5678” into “15263748+”.
startDigitMove {
equals digit: (1, digitMove), (1, startPhase2), (0, removeEquals);
}
removeEquals {
equals digit: 1;
}
digitMove {
digit digit: (1, digitMove), (1, digitMove2);
digit plus: (1, digitMove2);
}
digitMove2 {
digit digit: (1, digitMove2), (0, swapDigits);
digit plus digit: (2, digitMove2), (0, digitMove3);
digit plus equals: digit0 1 2;
plus digit: (1, digitMove2), (0, swapPlusDigit);
plus equals: digit0 1;
digit equals: 1;
}
swapDigits {
digit digit: 1 ;
}
digitMove3 {
digit plus digit: 2 1;
}
swapPlusDigit {
plus digit: 1 ;
}
The next step is to see if there were any glyphs left over on the right side that didn’t get moved. This happens if the right side is longer than the left side. For example, if the input string is “12+3456” we now would have “1526+34”. We want to turn this into “03041526”
startPhase2 {
digit digit: (0, phase2), (0, beginPhase3);
}
phase2 {
digit digit: (0, phase2Move), (0, checkPayload);
}
phase2Move {
digit digit digit digit: (2, phase2Move), (0, movePayload);
digit digit plus equals: 1 2 3;
digit digit plus digit: (3, payload), (0, flagPayload);
}
payload {
digit digit: (1, payload), (0, swapDigits);
digit equals: 1;
}
flagPayload {
digit digit plus digit: flag 3 1 2;
}
movePayload {
digit digit flag digit: 2 3 1;
}
checkPayload {
flag digit digit digit: (0, rearrangePayload), (0, phase2);
}
rearrangePayload {
flag digit digit digit: digit0 1 2 3;
}
The last step is to actually perform the addition. This works like a ripple carry adder. We want to take the glyphs two-at-a-time, and add them, and produce a carry. Then the next pair of glyphs will add, and include the carry. We start the process by introducing a carry = 0.
beginPhase3 {
digit digit: (0, phase3), (0, removeZero);
}
phase3 {
digit digit digit digit: (2, phase3), (0, addPair);
digit digit plus equals: (0, insertCarry), (0, addPair);
}
insertCarry {
digit digit plus equals: 1 digit0;
}
removeZero {
digit0 digit: (1, removeZero), (0, removeSingleZero);
}
removeSingleZero {
digit0 digit: 1;
}
addPair {
1 1 1: 1 1;
1 1 2: 1 2;
1 2 1: 1 2;
1 2 2: 1 3;
1 3 1: 1 3;
1 3 2: 1 4;
… more here
}
HarfBuzz
So I’m doing this whole thing using the HarfBuzz shaper, as described above. This is because it’s open source, so I can find where I’m hitting limits and increase the limits. It turned out that I not only had to increase the
HB_MAX_NESTING_LEVEL to
4294967294, but I also was running into more limits. I ended up just taking all the limits in
hb-buffer.hh,
hb-machinery.hh, and
hb-ot-layout-common.hh and increasing them by a factor of 10.
There’s one more piece that was necessary to get it to work. Inside apply_lookup() in hb-ot-layout-gsubgpos.hh, there’s a section if (end <= int (match_positions[idx])). It looks to me like this section is detecting if a recursive call caused the glyph sequence to get shorter than the size of the match. Inside this block, it says /* There can’t be any further changes. */ break; which seems to stop the recursion (which seems incorrect to me, but I’m not a HarfBuzz developer, so I could be wrong). In order to get this whole system to work, I had to comment out the “break” statement.
So that’s it! After doing that, the system works, and the font correctly adds numbers. The font has 75 shaping rules and is 32KB large.
The glyph paths (contours) were taken from from the Retroscape font.
